
【有卡有网】 4 月 22 日消息,微软公司近日发布新闻稿,正式揭晓了其创新的图生视频技术—— VASA-1 框架。这一 AI 框架仅需凭借一张真实的肖像照片和一段个人语音音频,便能打造出精确且逼真的对口型视频(即生成朗诵文本的视频)。

当前业界对传统的技术往往会导致生成的面部显得生硬、缺乏可信度,陷入“恐怖谷”现象。而微软的 VASA-1 框架则成功突破了这些限制,研究人员借助了扩散Transformer模型,对面部整体动态和头部运动进行了深入训练。
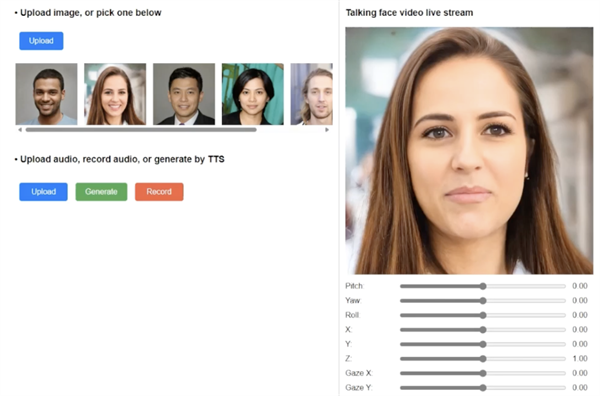
该框架在表情和头部动作方面的表现尤为自然流畅。能够注意到各类面部动态,诸如嘴唇动作、面部表情、眼神交流和眨眼等细微行为,一次性生成具有高度细节的人脸。据称,VASA-1框架能够即时生成分辨率为512×512、帧率高达40 FPS的视频。
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《微软推出最新AI框架,可生成逼真对口型人像视频》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106365.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《微软推出最新AI框架,可生成逼真对口型人像视频》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106365.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。



