
【有卡有网】 5 月 15 日消息,腾讯正式宣布,他们旗下的混元文生图大模型已完成升级并对外开放源代码,目前已在 HuggingFace 和 Gilhub 平台公开发布。

这一模型提供了完整的资源,包括模型权重、推理代局和摸型算法等,自在为企业和个人开发者提供免费商用机会。
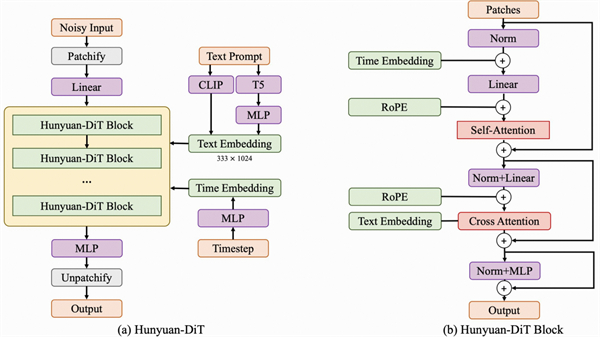
腾讯强调,混元 DiT 是业内首个中英双语 DiT 架构的模型,同时也是首个以中文为原生语言的文生图开源模型,能够支持中英文双语输入及埋释,拥有高达 15 亿的参数量。

要运行此模型,用户需要拥有支持 CUDA 的英伟达 GPU。独立运行混元 DiT 时,至少需要 11GB 的显存;而若同时运行腾讯推出的文本线图像多模态交互式对话系统 DialogGen 与混元 DiT,则需要至少 32 GB 的显存。
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《腾讯旗下混元文生图大模型对外开源》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106425.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《腾讯旗下混元文生图大模型对外开源》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106425.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。



