
【有卡有网】 6 月 21 日消息,据DeepMind新闻稿透露,DeepMind最新研发出一项“video-to-audio”AI模型技术,可为无声视频量身打造背景音乐。
目前该AI模型仍存局限,需开发者以提示词预先“描绘”视频可能的声响,尚不能直接依据视频画面添加具体音效。
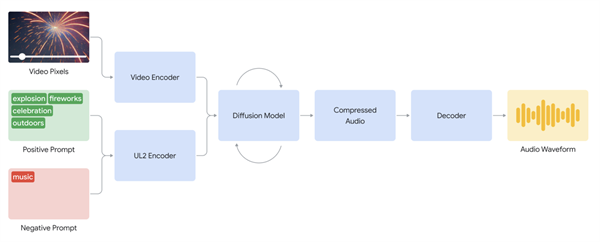
据悉,模型会先将用户输入的视频进行拆解,再结合用户提供的文字提示,通过扩散模型反复运算,最终生成与视频画面相协调的背景声音。
例如,输入一段“黑暗中行走”的无声视频,并添加“电影、恐怖片、紧张氛围、脚步声”等提示词,模型便能生成符合恐怖风格的背景音效。
DeepMind 同时表示,该“video-to-audio”模型可以为任何视频生成无限数量的音轨,还能够通过提示词内容判断生成的音频“正向性”或“反向性”,从而令生成的声音更贴近某些特定场景。
版权声明:本文采用知识共享 署名4.0国际许可协议 [BY-NC-SA] 进行授权
文章名称:《谷歌 DeepMind 公布为无声视频配音 AI 模型》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106497.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
文章名称:《谷歌 DeepMind 公布为无声视频配音 AI 模型》
文章链接:https://www.youkayouwang.com/it-keji/zhineng/106497.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。



